|
PLUTO
|
Miscellaneous functions for implementing the shearing-box boundary condition. More...
#include "pluto.h"
Go to the source code of this file.
Functions | |
| void | SB_SetBoundaryVar (double ***U, RBox *box, int side, double t, Grid *grid) |
| void | SB_FillBoundaryGhost (double ***U, RBox *box, int nghL, int nghR, Grid *grid) |
| void | SB_ShearingInterp (double *qL, double *qR, double t, int side, Grid *grid) |
| int | SB_JSHIFT (int jc) |
Variables | |
| static double | sb_Ly |
Miscellaneous functions for implementing the shearing-box boundary condition.
The shearing-box tool file contains various functions for the implementation of the shearingbox boundary conditions in serial or parallel mode. The SB_SetBoundaryVar() function applies shearing-box boundary conditions to a 3D array U[k][j][i] at an X1_BEG or X1_END boundary. The array U[k][j][i] is defined on the RBox *box with grid indices (box->ib) <= i <= (box->ie), (box->jb) <= j <= (box->je) (box->kb) <= k <= (box->ke), and assumes that periodic boundary conditions have already been set. Indices in the y-directions are not necessary, since the entire y-range is assumed.
In parallel mode, we use the SB_ShiftBoundaryVar() function to perform the integer shift of cells across the processors, while interpolation function SB_ShearingInterp() handles the fractional part only. In serial or when there's only 1 processor along y, the interpolation function does all the job (integer+fractional).
Definition in file sb_tools.c.
Fill ghost zones in the Y direction in the X1_BEG and X1_END boundary regions.
| [in,out] | U | a 3D data array |
| [in,out] | box | the RBox structure containing the grid indices in the x and z directions. Indices in the y-directions are reset here for convenience. |
| [in] | nghL | number of ghost zones on the left |
| [in] | nghR | number of ghost zones on the right |
| [in] | grid | pointer to an |
Definition at line 297 of file sb_tools.c.

| int SB_JSHIFT | ( | int | jc | ) |
Make sure jc always fall between JBEG and JEND
Definition at line 638 of file sb_tools.c.


Fill ghost zones using shearing-box conditions.
| [out] | U | pointer to a 3D array (centered or staggered) |
| [in] | box | pointer to RBox structure defining the domain sub-portion over which shearing-box conditions have to be applied |
| [in] | side | the side of the X1 boundary (X1_BEG or X1_END) |
| [in] | t | the simulation time |
| [in] | grid | pointer to an array of Grid structures |
Definition at line 36 of file sb_tools.c.
| void SB_ShearingInterp | ( | double * | qL, |
| double * | qR, | ||
| double | t, | ||
| int | side, | ||
| Grid * | grid | ||
| ) |
Shift the 1D arrays qL or qR by an amount 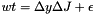 (if there's only one processor in y) or just by
(if there's only one processor in y) or just by 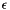 (otherwise) by advecting the initial profile of qR (when side == X1_BEG) or qL (when side == X1_END).
(otherwise) by advecting the initial profile of qR (when side == X1_BEG) or qL (when side == X1_END).
| [in,out] | qL | 1D array containing the un-shifted values on the left boundary |
| [in,out] | qR | 1D array containing the un-shifted values on the right boundary |
| [in] | t | simulation time |
| [in] | side | boundary side |
| [in] | grid | pointer to an array of Grid structures |
Definition at line 444 of file sb_tools.c.

|
static |
Definition at line 33 of file sb_tools.c.
 1.8.10
1.8.10 
