Shifts conserved variables in the orbital direction.
60 int i,
j,
k, nv, ngh, nvar_c;
62 static int mmax, mmin;
63 int nbuf_lower, nbuf_upper, nproc_s = 1;
64 double *dx, *dy, *dz, dphi;
65 double *x, *xp, *y, *yp, *z, *zp, w, Lphi, dL,
eps;
67 static double *q00, *flux00;
69 static double ***Ez, ***Ex;
71 double ***upper_buf[
NVAR];
72 double ***lower_buf[
NVAR];
76 #if GEOMETRY == CYLINDRICAL
77 print1 (
"! FARGO cannot be used in this geometry\n");
95 #if GEOMETRY == SPHERICAL && DIMENSIONS == 3
142 #if (HAVE_ENERGY) && (defined SHEARINGBOX)
168 nbuf_lower = abs(mmin) + ngh + 1;
169 nbuf_upper = mmax + ngh + 1;
173 if (nbuf_upper >
NS || nbuf_lower >
NS){
174 print (
"! FARGO_ShiftSolution: buffer size exceeds processsor size\n");
180 if (nbuf_upper > MAX_BUF_SIZE || nbuf_lower > MAX_BUF_SIZE){
181 print (
"! FARGO_ShiftSolution: buffer size exceeds maximum length\n");
187 #if GEOMETRY == CARTESIAN || GEOMETRY == POLAR
191 lbox.
di = lbox.
dj = lbox.
dk = 1;
195 ubox.
di = ubox.
dj = ubox.
dk = 1;
200 lbox.
kb--; ubox.
kb--;)
203 #elif GEOMETRY == SPHERICAL
207 lbox.
di = lbox.
dj = lbox.
dk = 1;
211 ubox.
di = ubox.
dj = ubox.
dk = 1;
215 lbox.
jb--; ubox.
jb--; ,
223 for (nv = 0; nv <
NVAR; nv++){
243 #if GEOMETRY == CARTESIAN || GEOMETRY == POLAR
249 #if GEOMETRY == CARTESIAN
251 #elif GEOMETRY == POLAR
253 #elif GEOMETRY == SPHERICAL
254 w = wA[
j][
i]/(x[
i]*sin(y[j]));
271 m = (int)floor(dL/dphi + 0.5);
277 if (w > 0.0 && (m + ngh) > nbuf_upper){
278 print1 (
"! FARGO_ShiftSolution: positive shift too large\n");
281 if (w < 0.0 && (-m + ngh) > nbuf_lower){
282 print1 (
"! FARGO_ShiftSolution: negative shift too large\n");
294 for (nv =
NVAR; nv--; ){
298 if (nv ==
BX2)
continue; ,
299 if (nv ==
BX3)
continue;)
317 for (
s = 1;
s <= ngh;
s++) {
330 U[
k][
j][
i][nv] = q[sm] - eps*(flux[sm] - flux[sm-1]);
336 U[
k][
j][
i][nv] = q[sm] - eps*(flux[sm] - flux[sm-1]);
349 double *Ar, *Ath, *dr, *r;
350 double ***bx1, ***bx2, ***bx3;
367 #if GEOMETRY == CARTESIAN || GEOMETRY == POLAR
370 JDOM_LOOP(j) for (i = IBEG-1; i <= IEND; i++){
373 #if GEOMETRY == CARTESIAN
374 w = 0.5*(wA[
k][
i] + wA[
k][i+1]);
375 #elif GEOMETRY == POLAR
376 w = 0.5*(wA[
k][
i] + wA[
k][i+1])/xp[i];
377 #elif GEOMETRY == SPHERICAL
378 w = 0.5*(wA[
j][
i] + wA[
j][i+1])/(xp[i]*sin(y[j]));
388 m = (int)floor(dL/dphi + 0.5);
405 for (
s = 1;
s <= ngh;
s++) {
419 Ez[
k][
j][
i] = eps*flux[sm];
420 for (ss =
s; ss > (
s-m); ss--) Ez[k][j][i] += q[ss];
426 Ez[
k][
j][
i] = eps*flux[sm];
427 for (ss =
s+1; ss < (
s-m+1); ss++) Ez[k][j][i] -= q[ss];
436 Ez[
k][
j][
i] = eps*flux[sm];
437 for (ss =
s; ss > (
s-m); ss--) Ez[k][j][i] += q[
FARGO_MOD(ss)];
443 Ez[
k][
j][
i] = eps*flux[sm];
444 for (ss =
s+1; ss < (
s-m+1); ss++) Ez[k][j][i] -= q[
FARGO_MOD(ss)];
458 #if GEOMETRY == CARTESIAN || GEOMETRY == POLAR
461 double ***bs = Us[
BX3s];
465 double ***bs = Us[
BX2s];
468 #if GEOMETRY == CARTESIAN
469 w = 0.5*(wA[
k][
i] + wA[k+1][
i]);
470 #elif GEOMETRY == POLAR
471 w = 0.5*(wA[
k][
i] + wA[k+1][
i])/x[i];;
472 #elif GEOMETRY == SPHERICAL
473 w = 0.5*(wA[
j][
i] + wA[j+1][
i])/(x[i]*sin(yp[j]));
483 m = (int)floor(dL/dphi + 0.5);
500 for (
s = 1;
s <= ngh;
s++) {
514 Ex[
k][
j][
i] = eps*flux[sm];
515 for (ss =
s; ss > (
s-m); ss--) Ex[k][j][i] += q[ss];
521 Ex[
k][
j][
i] = eps*flux[sm];
522 for (ss =
s+1; ss < (
s-m+1); ss++) Ex[k][j][i] -= q[ss];
531 Ex[
k][
j][
i] = eps*flux[sm];
532 for (ss =
s; ss > (
s-m); ss--) Ex[k][j][i] += q[
FARGO_MOD(ss)];
538 Ex[
k][
j][
i] = eps*flux[sm];
539 for (ss =
s+1; ss < (
s-m+1); ss++) Ex[k][j][i] -= q[
FARGO_MOD(ss)];
552 #if GEOMETRY == CARTESIAN || GEOMETRY == POLAR
553 bx1[
k][
j][
i] -= (Ez[
k][
j][
i] - Ez[
k][j-1][
i])/dphi;
554 #elif GEOMETRY == SPHERICAL
555 bx1[
k][
j][
i] -= (Ez[
k][
j][
i] - Ez[k-1][
j][
i])/dphi;
564 #if GEOMETRY == CARTESIAN
566 (Ez[k][j][i] - Ez[k][j][i-1])/dx[i] ,
567 - (Ex[k][j][i] - Ex[k-1][j][i])/dz[k]);
568 #elif GEOMETRY == POLAR
570 (Ar[i]*Ez[k][j][i] - Ar[i-1]*Ez[k][j][i-1])/dr[i] ,
571 - x[i]*(Ex[k][j][i] - Ex[k-1][j][i])/dz[k]);
573 #elif GEOMETRY == SPHERICAL
574 bx2[
k][
j][
i] += (Ex[
k][
j][
i] - Ex[k-1][
j][
i])/dphi;
584 #if GEOMETRY == CARTESIAN || GEOMETRY == POLAR
585 bx3[
k][
j][
i] += (Ex[
k][
j][
i] - Ex[
k][j-1][
i])/dphi;
586 #elif GEOMETRY == SPHERICAL
587 bx3[
k][
j][
i] += sin(y[j])*( Ar[
i]*Ez[
k][
j][
i]
588 - Ar[i-1]*Ez[
k][
j][i-1])/(r[i]*dr[i])
589 - (Ath[
j]*Ex[
k][
j][
i] - Ath[j-1]*Ex[
k][j-1][
i])/dy[j];
598 U[k][j][i][
BX1] = 0.5*(Us[
BX1s][k][j][i] + Us[
BX1s][k][j][i-1]); ,
608 for (nv = 0; nv <
NVAR; nv++){
#define FARGO_ARRAY_INDEX(A, s, k, j, i)
int jb
Lower corner index in the x2 direction.
void print1(const char *fmt,...)
long int NX2_TOT
Total number of zones in the X2 direction (boundaries included) for the local processor.
int kb
Lower corner index in the x3 direction.
void FreeArrayBox(double ***t, long nrl, long ncl, long ndl)
double g_dt
The current integration time step.
int dk
Directional increment (+1 or -1) when looping over the 3rd dimension of the box.
double *** ArrayBox(long int nrl, long int nrh, long int ncl, long int nch, long int ndl, long int ndh)
#define ARRAY_3D(nx, ny, nz, type)
int ib
Lower corner index in the x1 direction.
int dj
Directional increment (+1 or -1) when looping over the 2nd dimension of the box.
void FARGO_Source(Data_Arr, double, Grid *)
long int NX3_TOT
Total number of zones in the X3 direction (boundaries included) for the local processor.
int nghost
Number of ghost zones.
long int IEND
Upper grid index of the computational domain in the the X1 direction for the local processor...
void print(const char *fmt,...)
double g_domBeg[3]
Lower limits of the computational domain.
static void FARGO_Flux(double *, double *, double)
static void FARGO_ParallelExchange(Data_Arr U, Data_Arr Us, double ***rbl[], RBox *, double ***rbu[], RBox *, Grid *grid)
#define ARRAY_1D(nx, type)
D_EXPAND(tot/[n]=(double) grid[IDIR].np_int_glob;, tot/[n]=(double) grid[JDIR].np_int_glob;, tot/[n]=(double) grid[KDIR].np_int_glob;)
double ** FARGO_GetVelocity(void)
int ie
Upper corner index in the x1 direction.
int ke
Upper corner index in the x3 direction.
int je
Upper corner index in the x2 direction.
long int KBEG
Lower grid index of the computational domain in the the X3 direction for the local processor...
long int KEND
Upper grid index of the computational domain in the the X3 direction for the local processor...
int di
Directional increment (+1 or -1) when looping over the 1st dimension of the box.
double g_domEnd[3]
Upper limits of the computational domain.
long int JBEG
Lower grid index of the computational domain in the the X2 direction for the local processor...
#define QUIT_PLUTO(e_code)
long int JEND
Upper grid index of the computational domain in the the X2 direction for the local processor...
long int NX1_TOT
Total number of zones in the X1 direction (boundaries included) for the local processor.
int nproc
number of processors for this grid.
long int IBEG
Lower grid index of the computational domain in the the X1 direction for the local processor...
double * A
Right interface area, A[i] = .

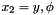 (for Cartesian or polar coordinates) or
(for Cartesian or polar coordinates) or 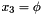 (for spherical coordinates). The shift is converted into an integer part "m" and a fractional remainder "eps".
(for spherical coordinates). The shift is converted into an integer part "m" and a fractional remainder "eps".



 1.8.10
1.8.10 
